So what does a masters degree look like in the UK if a US masters is catching up to UK undergrad



-
-
S&T Moderators: Skorpio | VerbalTruist
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Psychology IQ is largely a pseudoscientific swindle
- Thread starter Buzz Lightbeer
- Start date


So what does a masters degree look like in the UK if a US masters is catching up to UK undergrad

No but srs, it's typically 1 year in the UK, 2 in the US afaik.
Sometimes 1 or 1.5 here. The masters version of my program is 1
Electrum1
Bluelighter
- Joined
- Nov 22, 2021
- Messages
- 29,267
Anyone who drinks that much urine is low IQ
I guess I was wondering if there was a difference in content
I guess I was wondering if there was a difference in content
We used to have quite a few US students come over for a semester or two, sometimes a year (humanities/social sciences). The usual issues we had to work on were either (a) essay writing style - many were some way behind when it came to writing, and it was really just about the comparative lack of practice they'd had (leading to immature critical skills, argument styles etc); or (b) developing independent research skills - so basically not relying on spoon-fed info from your teacher and figuring it out yourself.
In terms of content, as long as they had a fundamental grasp of the subject, they could usually paper over the gaps pretty quickly by reading extensively. More often than not, certain modules would be new to everyone, so it really didn't matter that much. Where a class really did require pre-existing knowledge, it would usually not be an option in the first place unless they could demonstrate the necessary background.
For subjects where education tends to be more linear and specific - physics, maths etc - my understanding is it would be a case of giving them the summer to catch up via summer school with pass/fail exams at the end.
Nightraver
Bluelighter
- Joined
- Aug 29, 2016
- Messages
- 902
I personally have an IQ of 148 and I think I’m dumb as fck it’s not so much how much you know as how fast you can see a way round problems and it’s something I personally believe has a direct correlation between hi IQ and drug abuse. Speaking for myself I have always felt as if I was looking for an off switch and some of the biggest addicts I know are way higher than me in this regard. I think the problem that most of us have is that We are clearly clever enough to see how fucked this world and it’s principalities is But not clever enough to fix it. So when we feel that warm calm (some get it from benzo some from opioids) it’s like a break from the constant agitation that this brings us and we end up seeking it more the more we realise how fckd up this planet and it’s human peoples.
I hope someone else sees this too as I would feel like less of a freak if I knew I wasn’t alone in this feeling
I hope someone else sees this too as I would feel like less of a freak if I knew I wasn’t alone in this feeling
SpiralusSancti
Bluelighter
Too smart to be sober, ain't it?I personally have an IQ of 148 and I think I’m dumb as fck it’s not so much how much you know as how fast you can see a way round problems and it’s something I personally believe has a direct correlation between hi IQ and drug abuse. Speaking for myself I have always felt as if I was looking for an off switch and some of the biggest addicts I know are way higher than me in this regard. I think the problem that most of us have is that We are clearly clever enough to see how fucked this world and it’s principalities is But not clever enough to fix it. So when we feel that warm calm (some get it from benzo some from opioids) it’s like a break from the constant agitation that this brings us and we end up seeking it more the more we realise how fckd up this planet and it’s human peoples.
I hope someone else sees this too as I would feel like less of a freak if I knew I wasn’t alone in this feeling

jasperkent
Bluelighter
The best measurements for intelligence are biorhythms and astrological readings.
If you believe in either of these things, you are stupid. If you believe in both, you are really stupid.
If you believe in either of these things, you are stupid. If you believe in both, you are really stupid.
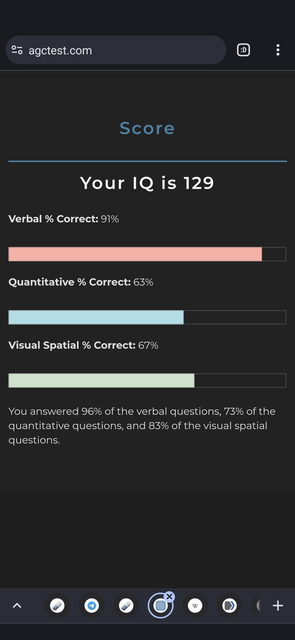
That's what I get for smoking all day, I couldn't even finish ffs
I feel like SAT scores are one of the best proxies for IQ given the sheer number of test takers. No other standardized test is as widely administered as the SAT.
The problem is, it only gives you an estimate of IQ if the test taker actually put in effort. But a huge number of people put considerable effort, and the effect of studying only alters the outcome to a limited degree. For instance, no one who gets a score of 1000 on their first diligent attempt will be able to increase their score to 1500 by studying.
Of course, I say this because I got an almost perfect score , but nonetheless, if I were evaluating the intelligence of a person based on a self-reported IQ score and an SAT score, I'd put far more weight in the SAT score since the number is more reliable.
, but nonetheless, if I were evaluating the intelligence of a person based on a self-reported IQ score and an SAT score, I'd put far more weight in the SAT score since the number is more reliable.
The other limitation of SAT scores as a proxy for IQ is that it won’t give detail on those with potentially extremely high IQ (beyond +3 standard deviations), so it's only able to give one an estimate up to an IQ of "150".
Interestingly, because I went to a prep school, two people in my class actually got slightly higher scores than I did: one kid got a 1590 and some girl got a perfect 1600. The three of us did not do nearly as well in life as the kids who got scores in the 1400-1500 range (those that wound up becoming doctors and lawyers were in that range). Of the ultra high scorers, the kid who got the 1590 went to Yale and suffered a psychiatric meltdown in his first year (from which he never recovered), the girl with the 1600 is currently unemployed and has little overall employment history (based on her LinkedIn), and of course at a young age I developed a raging drug addiction that I didn't defeat until my late 20s. Compared to those two I'm the successful one I suppose, but I still lag far behind the 1400-1500 scoring crew. Having a high IQ seems more conducive to success than a very high IQ.
The problem is, it only gives you an estimate of IQ if the test taker actually put in effort. But a huge number of people put considerable effort, and the effect of studying only alters the outcome to a limited degree. For instance, no one who gets a score of 1000 on their first diligent attempt will be able to increase their score to 1500 by studying.
Of course, I say this because I got an almost perfect score
, but nonetheless, if I were evaluating the intelligence of a person based on a self-reported IQ score and an SAT score, I'd put far more weight in the SAT score since the number is more reliable.The other limitation of SAT scores as a proxy for IQ is that it won’t give detail on those with potentially extremely high IQ (beyond +3 standard deviations), so it's only able to give one an estimate up to an IQ of "150".
Interestingly, because I went to a prep school, two people in my class actually got slightly higher scores than I did: one kid got a 1590 and some girl got a perfect 1600. The three of us did not do nearly as well in life as the kids who got scores in the 1400-1500 range (those that wound up becoming doctors and lawyers were in that range). Of the ultra high scorers, the kid who got the 1590 went to Yale and suffered a psychiatric meltdown in his first year (from which he never recovered), the girl with the 1600 is currently unemployed and has little overall employment history (based on her LinkedIn), and of course at a young age I developed a raging drug addiction that I didn't defeat until my late 20s. Compared to those two I'm the successful one I suppose, but I still lag far behind the 1400-1500 scoring crew. Having a high IQ seems more conducive to success than a very high IQ.
I have no idea what my IQ is according to genuine tests undertaken by professionals. I was given one at school when I was about 11/12 due to depression and 'mood issues', but they never gave me the score. However, I do remember I couldn't process or recall even pretty basic stuff during the test, which in retrospect I would attribute to ADHD-type panic, which made my mind completely blank and cognition virtually impossible, and thus any 'number' would have been fairly meaningless anyway.
When it came to exams where performance against others could be directly compared, I really did no study at all until about the week or so before all my GSCEs and A-Levels (eh, final subject exams we take in the UK at ages 16 and 18). And then I got all A*s in everything and the highest grades (well, 'top 5') in the country in 2 subjects. Which was a big surprise to my teachers, who had mostly predicted Bs, Cs, Ds and so on based on my prior boredom and lack of study lol. Turns out those of us with ADHD need a little pressure to get going!
When it came to exams where performance against others could be directly compared, I really did no study at all until about the week or so before all my GSCEs and A-Levels (eh, final subject exams we take in the UK at ages 16 and 18). And then I got all A*s in everything and the highest grades (well, 'top 5') in the country in 2 subjects. Which was a big surprise to my teachers, who had mostly predicted Bs, Cs, Ds and so on based on my prior boredom and lack of study lol. Turns out those of us with ADHD need a little pressure to get going!
Electrum1
Bluelighter
- Joined
- Nov 22, 2021
- Messages
- 29,267
"We show personality as less important than intelligence in predicting life outcomes"
"For pay the predictive validity of intelligence was twice as high as that of personality"
"For educational attainment and grades it was 4.4 and 5.2 times as high"
"For pay the predictive validity of intelligence was twice as high as that of personality"
"For educational attainment and grades it was 4.4 and 5.2 times as high"
Electrum1
Bluelighter
- Joined
- Nov 22, 2021
- Messages
- 29,267
From something I'm reading right now
How does intelligence even work at a genetic level?
Our best estimate based on the last decade of data is that the genetic component of intelligence is controlled by somewhere between 10,000 and 24,000 variants. We also know that each one, on average, contributes about +-0.2 IQ points.
Genetically altering IQ is more or less about flipping a sufficient number of IQ-decreasing variants to their IQ-increasing counterparts. This sounds overly simplified, but it’s surprisingly accurate; most of the variance in the genome is linear in nature, by which I mean the effect of a gene doesn’t usually depend on which other genes are present.
So modeling a continuous trait like intelligence is actually extremely straightforward: you simply add the effects of the IQ-increasing alleles to to those of the IQ-decreasing alleles and then normalize the score relative to some reference group.
To simulate the effects of editing on intelligence, we’ve built a model based on summary statistics from UK Biobank, the assumptions behind which you can find in the appendix
Based on the model, we can come to a surprising conclusion: there is enough genetic variance in the human population to create a genome with a predicted IQ of about 900. I don’t expect such an IQ to actually result from flipping all IQ-decreasing alleles to their IQ-increasing variants for the same reason I don’t expect to reach the moon by climbing a very tall ladder; at some point, the simple linear model will break down.
But we have strong evidence that such models function quite well within the current human range, and likely somewhat beyond it. So we should actually be able to genetically engineer people with greater cognitive abilities than anyone who’s ever lived, and do so without necessarily making any great trade-offs.
Even if a majority of iq-increasing genetic variants had some tradeoff such as increasing disease risk (which current evidence suggests they mostly don’t), we could always select the subset that doesn’t produce such effects. After all, we have 800 IQ points worth of variants to choose from!
Total maximum gain
Given the current set of publicly available intelligence-associated variants available in UK biobank, here’s a graph showing the expected effect on IQ from editing genes in adults.
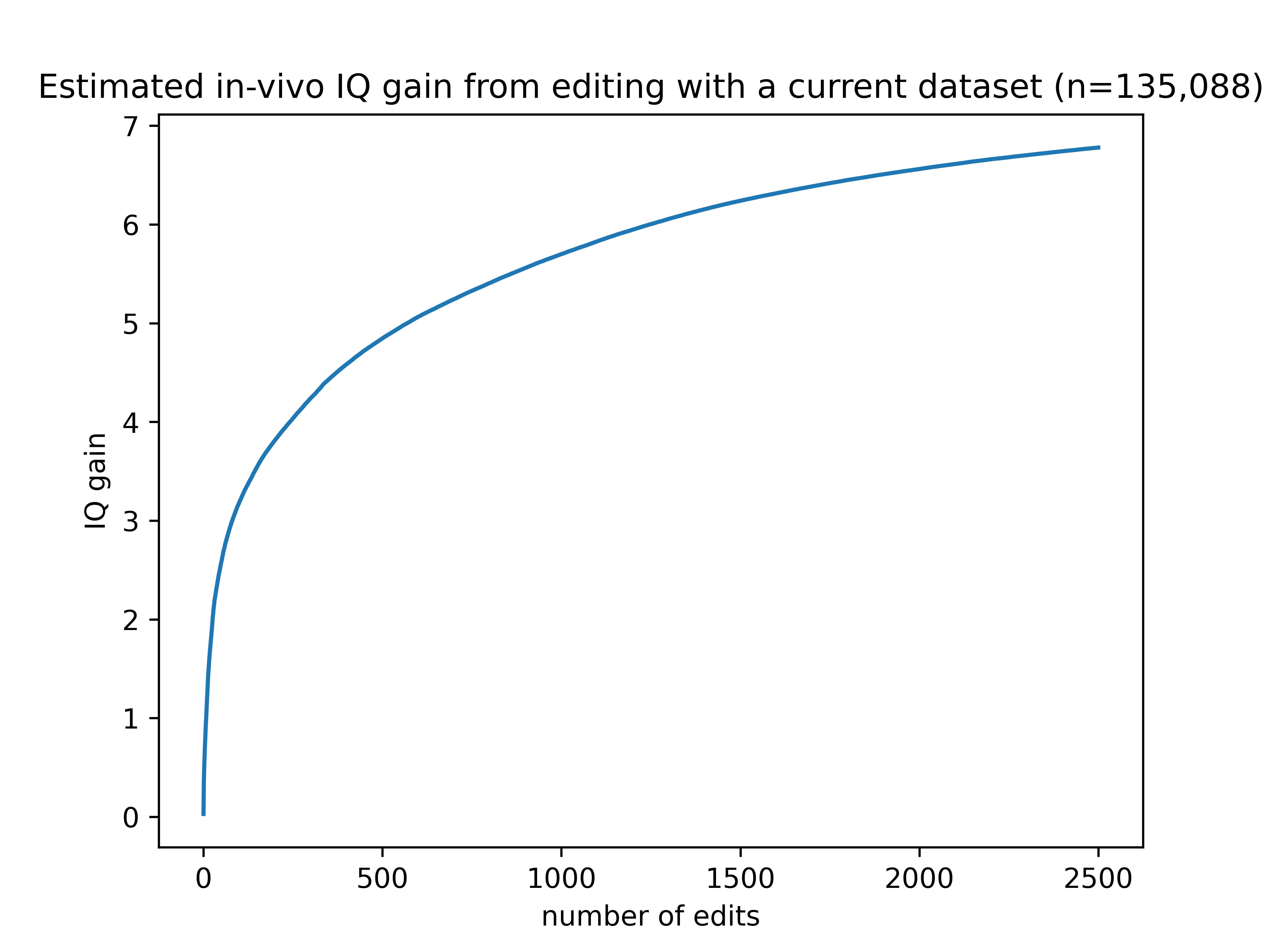
Not very impressive! There are several factors at play deflating the benefits shown by this graph.
The limitations in 1-5 together reduce the estimated effect size by 79% compared to making perfect edits in an embryo. If you could make those same edits in an embryo, the gains would top out around 30 IQ points.
- As a rough estimate, we expect about 50% of the targeted edits to be successfully made in an average brain cell. The actual amount could be more or less depending on editor and delivery efficiency.
- Some genes we know are involved in intelligence will have zero effect if edited in adults because they primarily influence brain development (see here for more details). Though there is substantial uncertainty here, we are assuming that, on average, an intelligence-affecting variant will have only 50% of the effect size as it would if edited in an embryo.
- We can only target about 90% of genetic variants with prime editors.
- About 98% of intelligence-affecting alleles are in non-protein-coding regions. The remaining 2% of variants are in protein-coding regions and are probably not safe to target with current editing tools due to the risk of frameshift mutations.
- Off-target edits, insertions and deletions will probably have some negative effect. As a very rough guess, we can probably maintain 95% of the benefit after the negative effects of these are taken into account.
- Most importantly, the current intelligence predictors only identify a small subset of intelligence-affecting genetic variants. With more data we can dramatically increase the benefit from editing for intelligence. The same goes for many other traits such as Alzheimer’s risk or depression.
But the bigger limitation originates from the size of the data set used to train our predictor. The more data used to train an intelligence predictor, the more of those 20,000 IQ-affecting variants we can identify, and the more certain we can be about exactly which variant among a cluster is actually causing the effect.
And the more edits you can make, the better you can take advantage of that additional data. You can see this demonstrated pretty clearly in the graph below, where each line represents a differently sized training set.
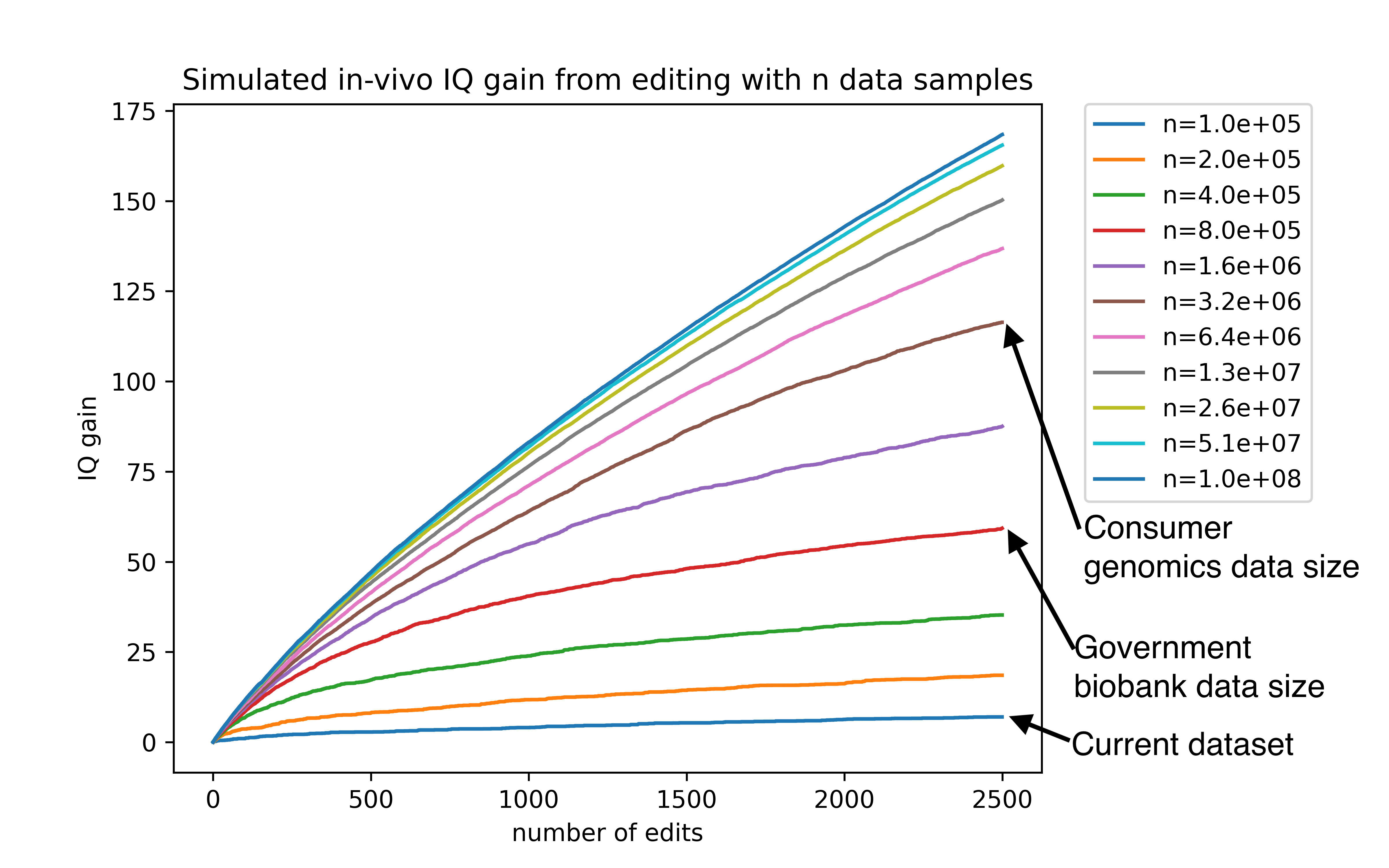
Our current predictors are trained using about 135,000 samples, which would place it just above the lowest line on the graph. There are existing databases right now such as the million veterans project with sample sizes of (you guessed it) one million. A predictor trained with that data would fall between the red and purple lines in the graph above.
Companies like 23&Me genotyped their 12 millionth customer two years ago and could probably get at perhaps 3 million customers to take an IQ test or submit SAT scores. A predictor trained with that amount of data would perform about as well as the brown line on the graph above.
So larger datasets could increase the effect of editing by as much as 13x! If we hold the number of edits performed constant at 2500, here’s how the expected gain would vary as a function of training set size:
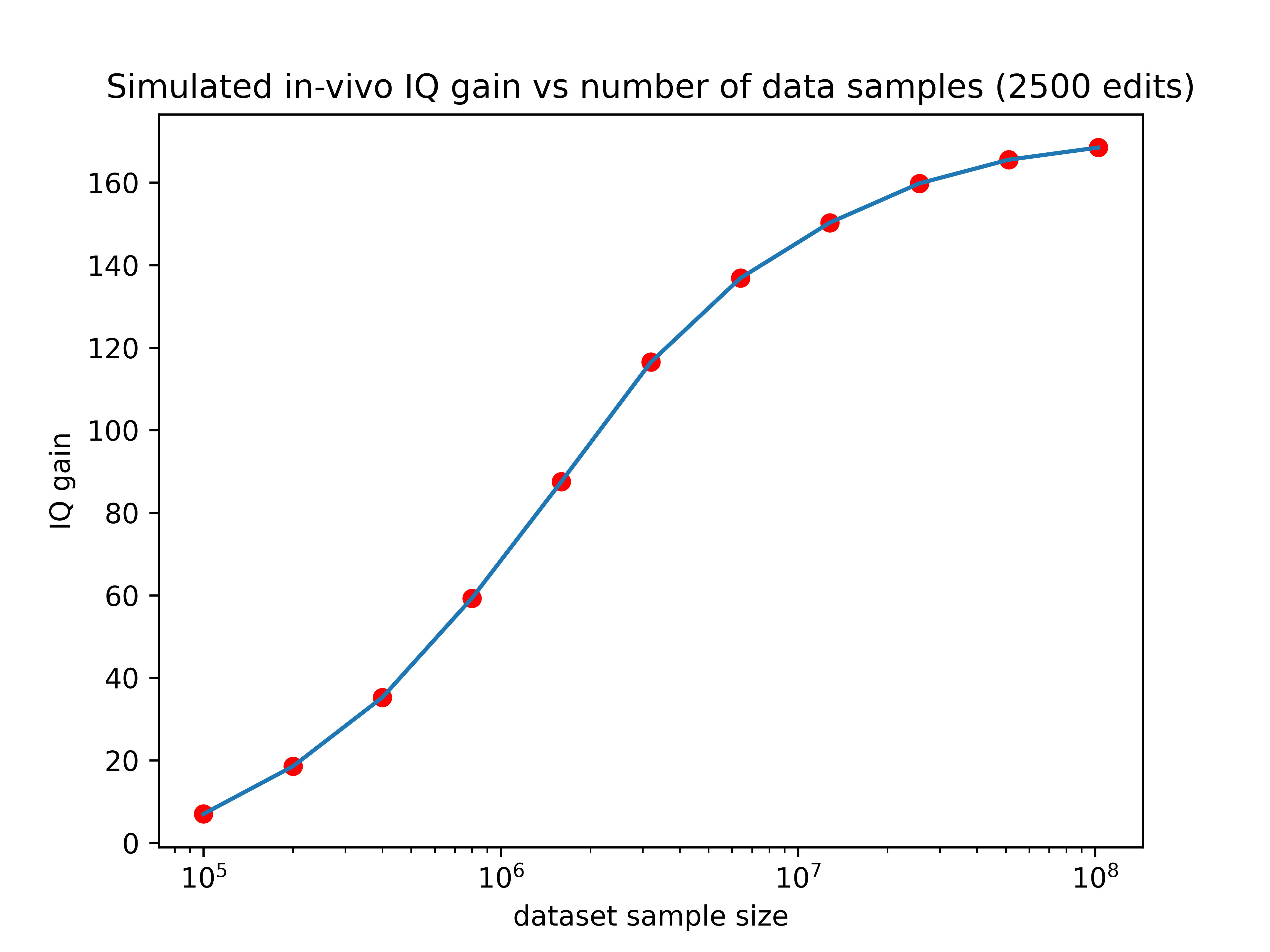
Now we’re talking! If someone made a training set with 3 million data points (a realistic possibility for companies like 23&Me), the IQ gain could plausibly be over 100 points (though keep in mind the uncertainties listed in the numbered list above). Even if we can only make 10% of that many edits, the expected effect size would still be over one standard deviation.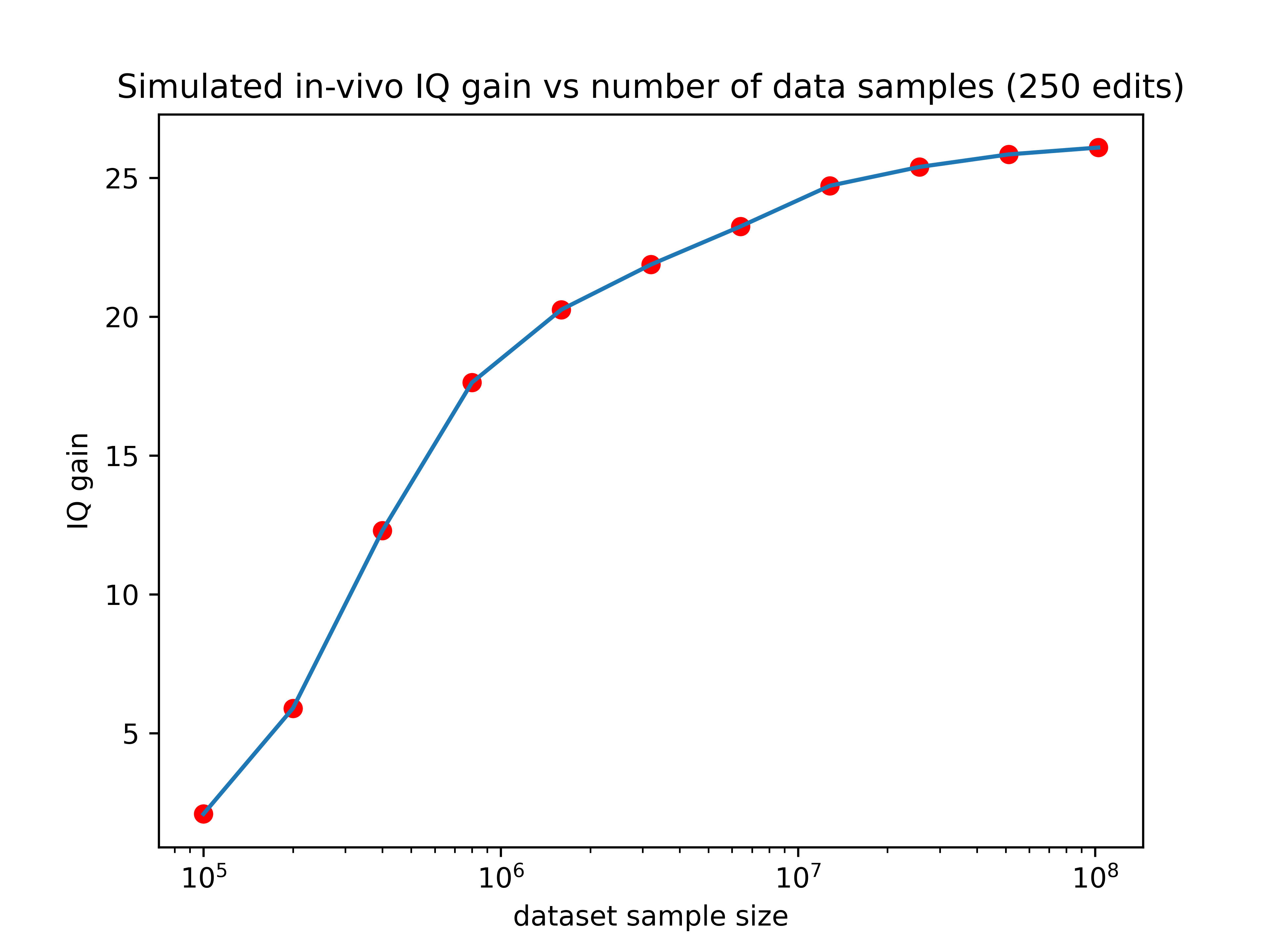
Electrum1
Bluelighter
- Joined
- Nov 22, 2021
- Messages
- 29,267
Intelligent brains take longer to solve difficult problems - News - BIH at Charité
Do intelligent people think faster? Researchers at the BIH and Charité – Universitätsmedizin Berlin, together with a colleague from Barcelona, made the surprising finding that participants with higher intelligence scores were only quicker when tackling simple tasks, while they took longer to...
AlsoTapered
Bluelighter
Often problems have multiple solutions. I know some VERY practical people who can find almost optimal solutions immediately. But they just need A solution.
For over two decades I was a professional computer game programmer and so the key was to find the OPTIMAL solution.
I've been looking at one problem for over two years because I'm almost sure it IS possible... but nobody has found it YET.
It's simply a 32-bit x 32-bit multiplication in which only the top 32-bits are needed and it's specifically for the ARM Thumb instruction-set.
ARM's own compiler takes 23 instructions/23 cycles (since no branches) and I've reduced that to 17... BUT I feel in my bones that their exists a 16 cycle methodology. So I keep coming back to it.
Why? Because ARM advised me that IF I found a way to do this, they would pay £5000 since they can use it in their compiler and suddenly every app that is written using their compiler gets a little faster.
Speed is everything. I've often wondered if AI could be employed BUT as it turns out, the Thumb instruction-set has some peculiar instruction possibilities and even ARM don't actually know them all... So step 1 would require fuzzing just to confirm what every valid instruction ACTUALLY does.
I might add that these are instructions that their compilers don't make use of.
RORS R0,R0,R0 is one example.
Rotating the value in R0 by the value of R0 into R0... But even the manuals and emulators state that bits 0-7 are used to set the rotate amount although any more than 31 (bits 0-4) shouldn't find a use... but they DO and produce undocumented results. Odd.
For over two decades I was a professional computer game programmer and so the key was to find the OPTIMAL solution.
I've been looking at one problem for over two years because I'm almost sure it IS possible... but nobody has found it YET.
It's simply a 32-bit x 32-bit multiplication in which only the top 32-bits are needed and it's specifically for the ARM Thumb instruction-set.
ARM's own compiler takes 23 instructions/23 cycles (since no branches) and I've reduced that to 17... BUT I feel in my bones that their exists a 16 cycle methodology. So I keep coming back to it.
Why? Because ARM advised me that IF I found a way to do this, they would pay £5000 since they can use it in their compiler and suddenly every app that is written using their compiler gets a little faster.
Speed is everything. I've often wondered if AI could be employed BUT as it turns out, the Thumb instruction-set has some peculiar instruction possibilities and even ARM don't actually know them all... So step 1 would require fuzzing just to confirm what every valid instruction ACTUALLY does.
I might add that these are instructions that their compilers don't make use of.
RORS R0,R0,R0 is one example.
Rotating the value in R0 by the value of R0 into R0... But even the manuals and emulators state that bits 0-7 are used to set the rotate amount although any more than 31 (bits 0-4) shouldn't find a use... but they DO and produce undocumented results. Odd.
Electrum1
Bluelighter
- Joined
- Nov 22, 2021
- Messages
- 29,267
16.3% perpetration of violence rate with IQ between 70 and 79
2.9% perpetration of violence rate with IQ between 120 and 129

 www.cambridge.org
www.cambridge.org
2.9% perpetration of violence rate with IQ between 120 and 129
There were 6872 participants aged ⩾16 years included in this study. The prevalence of violence perpetration decreased linearly with increasing IQ [16.3% (IQ 70–79) v. 2.9% (IQ 120–129)]. After adjusting for demographic and behavioral factors, childhood adversity, and psychiatric morbidity, compared with those with IQ 120–129, IQ scores of 110–119, 100–109, 90–99, 80–89, and 70–79 were associated with 1.07 [95% confidence interval (CI) 0.63–1.84], 1.90 (95% CI 1.12–3.22), 1.80 (95% CI 1.05–3.13), 2.36 (95% CI 1.32–4.22), and 2.25 (95% CI 1.26–4.01) times higher odds for violence perpetration, respectively
Association between intelligence quotient and violence perpetration in the English general population | Psychological Medicine | Cambridge Core
Association between intelligence quotient and violence perpetration in the English general population - Volume 49 Issue 8
Opi_Kid_Rock
Bluelighter
Why is it that someone would deny the existence of other types of intelligences like musical, language, emotional, kinetic, social? I don’t remember specifically the types.
AlsoTapered
Bluelighter
Why is it that someone would deny the existence of other types of intelligences like musical, language, emotional, kinetic, social? I don’t remember specifically the types.
Howard Gardner listed 9 types in his book but that's a 40 year old concept that's become known in the popular media.
- Logical-Mathematical Intelligence
- Linguistic Intelligence
- Interpersonal Intelligence
- Intrapersonal Intelligence
- Musical Intelligence
- Visual-Spatial Intelligence
- Bodily-Kinaesthetic Intelligence
- Naturalist Intelligence
- Existential Intelligence
I think being able to contemplate questions to which their might NOT be an answer isn't useful for survival thus I suppose it could be placed in the Self-Actualization region )as an example).